ComfyUI.Tokyo
SD1.5 VAE CLIP
ComfyUIのStable Diffusion 1.5 (SD1.5) において clip-vit-large-patch14.safetensors を用いることには、画像生成においていくつかのメリットがあります。
主なメリット
- より良いプロンプト理解と画像生成の整合性: clip-vit-large-patch14 は、元々CLIPモデルの一部であり、非常に大規模なデータセットで学習されています。これにより、テキストプロンプトの意味をより深く理解し、そのテキストに合致する画像を生成する能力が向上します。特に複雑なプロンプトや、特定の要素を細かく指定したい場合に、その効果が顕著になります。
- 詳細表現の向上: プロンプトの理解度が上がることで、生成される画像における細部の表現力も向上する傾向があります。例えば、特定の服装のディテールや、背景の要素などが、より正確に、かつ自然に描かれることが期待できます。
- 多様なコンセプトへの対応力: CLIPモデルが持つ広範な知識により、より多様なコンセプトやスタイルの画像を生成する際に、モデルがプロンプトから意図を汲み取りやすくなります。
注意点と考慮事項
- ファイルサイズとVRAM使用量: clip-vit-large-patch14.safetensors は、clip-vit-b などと比較してファイルサイズが大きく、VRAM使用量も増加する可能性があります。特にVRAMが限られている環境では、この点がボトルネックになる可能性があります。
- 生成速度への影響: モデルの規模が大きいため、わずかながら画像生成速度に影響を与える可能性もゼロではありません。ただし、ComfyUIは最適化されているため、体感できるほどの大きな差ではないことが多いです。
- 基本的な画像生成における体感差: ごく基本的な、シンプルなプロンプトによる画像生成の場合、clip-vit-large-patch14 を使用しなくても十分な品質の画像が得られることもあります。メリットをより強く感じるのは、前述のような複雑なプロンプトや、特定のニュアンスを伝えたい場合が多いでしょう。
結論として、ComfyUI SD1.5での典型的・基礎的な画像生成においても、clip-vit-large-patch14.safetensors を用いることは、プロンプトの理解度向上と、それによる生成画像の品質(特に詳細表現やプロンプトとの整合性)の向上が期待できるため、一般的にはメリットがあると言えます。
clip-vit-large-patch14 は、model.safetensorsを clip-vit-large-patch14.safetensorsに名前を変えれば、他のmodelと混乱しなくてすむかもしれません。
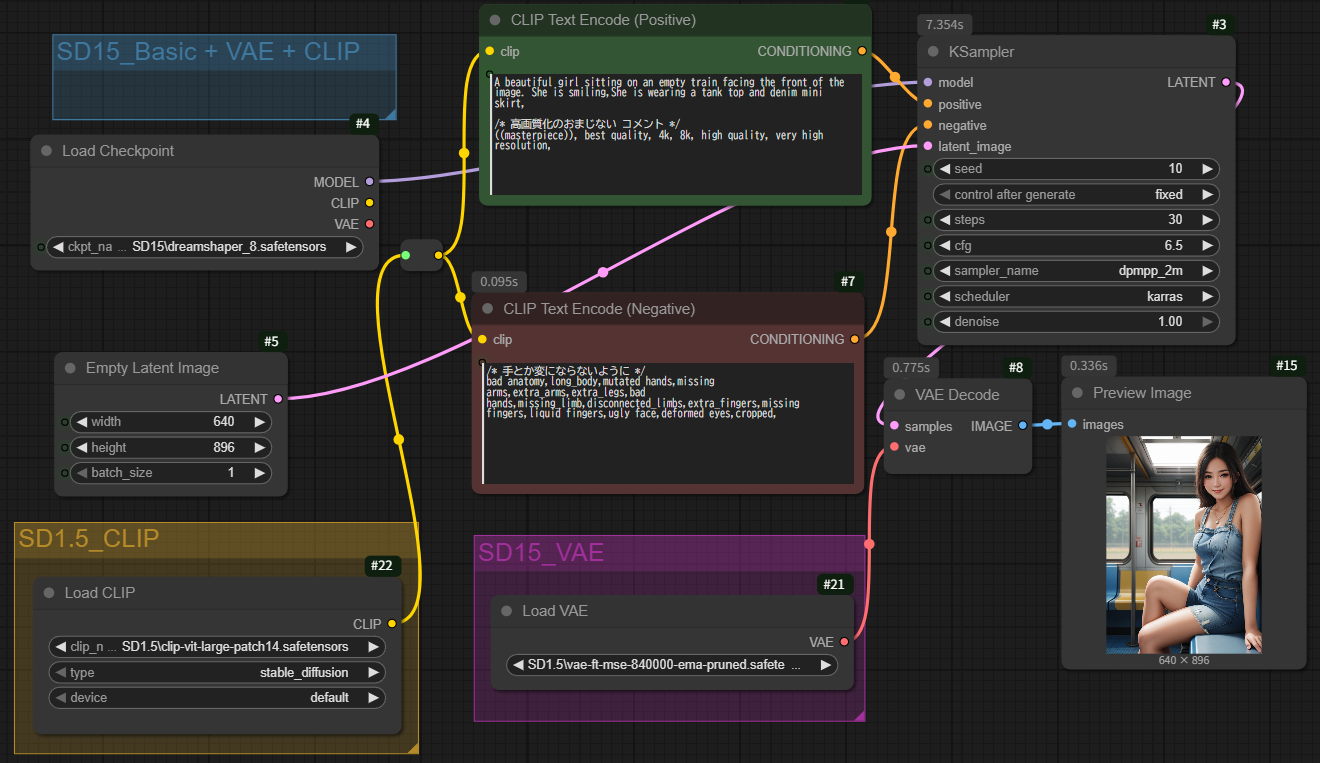
workflow


checkpointを beautifulRalistic_v7.safetensrs に変えた画像です。
【embedding:badhandv4】
手が変なときはbadhandv4.safetansorsを、comofyUI/models/loras フォルダににダウンロードして、ネガティブプロンプトに embedding:badhandv4, を追加します。
【bad-hands-5.pt】