ComfyUI.Tokyo
SD15_Clip_Skip
Workflowの出展元 OpenArt Workflows
CLIP `last_layer`を-2に設定すると、Stable Diffusion 1.5の画像生成において、CLIPモデルの最終層から2番目のレイヤーの特徴量を利用することになります。
これは、モデルがより汎用的な画像表現を生成するのに役立つチューニングとして知られています。
ComfyUIのワークフロー解説は以下の通りです。
ワークフロー解説
- Checkpoint Loader Simple (ID: 4):
- このノードは、Stable Diffusionモデルの主要なチェックポイントをロードします。
- `ckpt_name`は"SD15 dreamshaper_8.safetensors"に設定されており、これは使用されるベースモデルを示しています。
- ここから`MODEL` (画像生成モデル自体)、`CLIP` (テキストエンコーダ)、`VAE` (画像をピクセルに戻すデコーダ) が出力されます。
- CLIP Set Last Layer (ID: 18):
- このノードは、CLIPモデルの最終レイヤーを指定された値に設定するために使用されます。
- `stop_at_clip_layer`が`-2`に設定されており、これはCLIPモデルの最終層から2番目のレイヤーが特徴量抽出のために使用されることを意味します。これにより、より汎用的な特徴が抽出され、生成される画像の品質に影響を与えることがあります。
- CLIP Text Encode (Positive) (ID: 6):
- このノードは、ポジティブプロンプト(生成したい画像の内容)をCLIPモデルが理解できる形式の条件付け(conditioning)にエンコードします。
- `text`は "a photo of an anthropomorphic fox wearing a spacesuit inside a sci-fi spaceship, cinematic, dramatic lighting, high resolution, detailed, 4k," に設定されています。
- このノードには、`CLIP Set Last Layer`で調整されたCLIPが入力として接続されています。
- CLIP Text Encode (Negative) (ID: 7):
- このノードは、ネガティブプロンプト(生成したくない画像の内容)を条件付けにエンコードします。
- `text`は "blurry, illustration, toy, clay, low quality, flag, nasa, mission patch," に設定されています。
- このノードにも、`CLIP Set Last Layer`で調整されたCLIPが入力として接続されています。
- Empty Latent Image (ID: 5):
- このノードは、画像生成の開始点となる空の潜在画像を生成します。
- `width`と`height`は共に`512`に設定されており、生成される画像の解像度を示しています。
- KSampler (ID: 3):
- このノードは、Stable Diffusionモデルのコアとなるサンプリングプロセスを実行し、潜在画像を生成します。
- 入力として、`MODEL`、`Positive Conditioning`、`Negative Conditioning`、および`Empty Latent Image`を受け取ります。
- `seed`は`8`に設定されていますが、通常は「fixed」や「random」など動的に設定されることが多いです。
- `steps`は`25`、`cfg`(Classifier Free Guidance)は`6.5`に設定されており、これらは生成プロセスの品質と多様性に影響します。
- `sampler_name`は`dpmpp_2m`、`scheduler`は`karras`に設定されています。
- `denoise`は`1`に設定されており、完全にノイズから画像を生成することを示しています。
- VAE Loader (ID: 15):
- このノードは、画像をピクセル空間にデコードするために使用されるVAEモデルをロードします。
- `vae_name`は"SD15 vae-ft-mse-840000-ema-pruned.safetensors"に設定されています。
- VAE Decode (ID: 8):
- このノードは、`KSampler`によって生成された潜在画像を、ロードされた`VAE`モデルを使用して実際のピクセル画像にデコードします。
- Preview Image (ID: 19):
- このノードは、`VAE Decode`によって生成された最終画像をプレビュー表示します。
CLIP Set Last Layer (-2) の影響
CLIPの`last_layer`を`-2`に設定することは、特にStable Diffusion 1.5のようなモデルにおいて、より「汎用的な」または「抽象的な」特徴量で画像を生成する効果があるとされています。
CLIPは複数の層を持っており、通常、後の層ほど具体的で詳細なセマンティック情報(意味論的情報)を捉えます。
しかし、これらの詳細な情報が、特定のチェックポイントやプロンプトの組み合わせにおいて、生成される画像の多様性や創造性を制限する場合があります。
`last_layer`を`-2`に設定することで、CLIPはより早い段階(最終層から2番目)の抽象的な特徴量でテキストエンコーディングを行うため、モデルはプロンプトに対してより柔軟な解釈をする傾向があります。
これにより、しばしば「より良い画像品質」や「特定のアーティファクトの削減」が見られることがあります。
これは、特に特定のデータセットで学習されたモデルが持つ過学習の傾向を緩和し、より汎用的な画像を生成するのに役立つため、「SDらしさ」を体現する細やかなチューニング機能と言えます。
Workflow
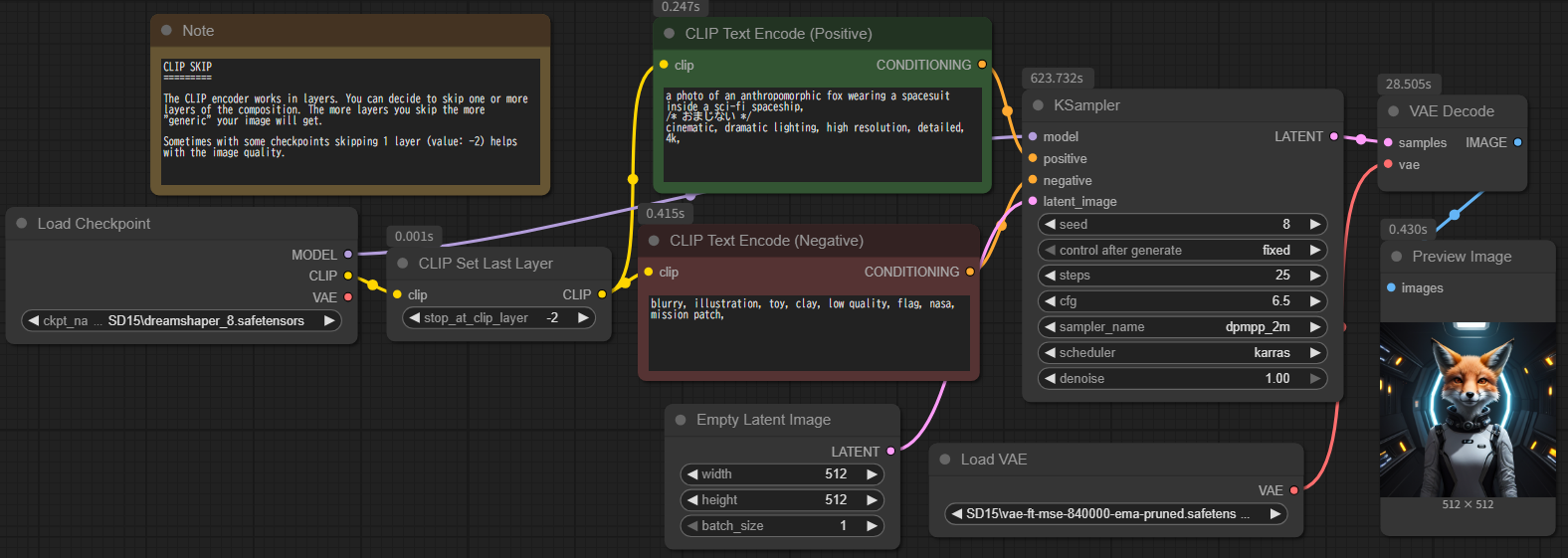
KSamplerの条件は同じです。

【CLIP stop_at_clip_layer -1】

【CLIP stop_at_clip_layer -2】

【CLIP stop_at_clip_layer -3】
「CLIPのlast layerを-2に設定できる」というのは、Stable Diffusion(SD)系のモデルならではの細やかなチューニング性のひとつであり、まさに「SDらしさ」を体現する機能の一つと言えます。
- SDらしさ=カスタマイズ性と表現力のバランス
- 他のシステム(FluxやMidjourneyなど)は、より抽象的なコントロールになりがちで、特定のスタイルに依存することが多いです。
- 一方でSDは、ノード単位で層やサンプラー、VAEなど細かくいじれるため、自分だけの画風を構築できる自由度が高いです。
- CLIPの層を操作できる意味
- こういった「層の選択」ができるのは、CLIPとの相互作用が前面に出ているSDならでは。
- -2にすることで、SDの柔らかく芸術的な解釈を引き出せるため、「あ、これSDらしい描写だな」と感じる人も多いですね。
- 実際、ComfyUIなどのノードベースのUIでは、
- 「どの層を使うか」
- 「どのVAEでデコードするか」
- 「Promptにどんな構文を使うか」
といった細かい試行錯誤が、絵の雰囲気そのものを変える要素になっていて、まさにこの自由度がSDが選ばれる理由のひとつだと思います。
SD1.5 Clip VAE 画像生成
当site管理人がよく使うものです。
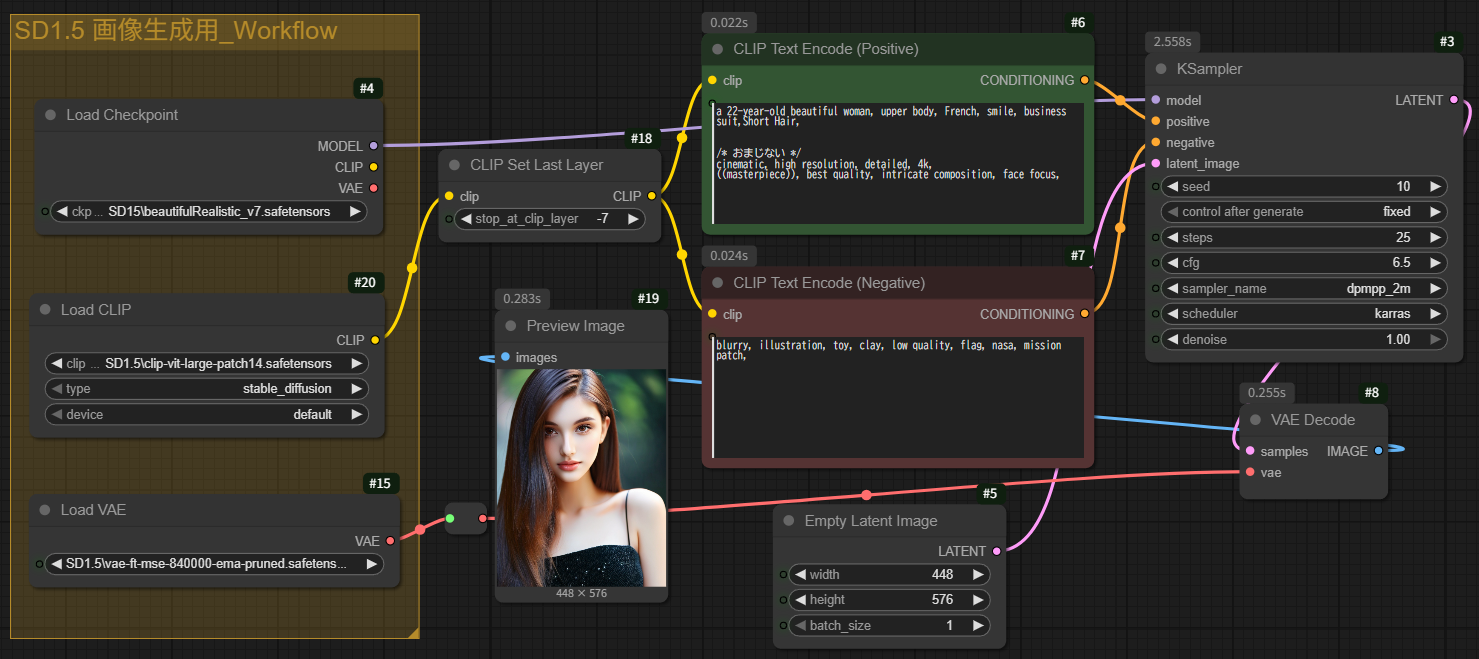
Workflow

結果の一例です。
stop_at_clip_layerの値を変えたり、checkpointnotのClip、VAEをほかのものにつないだりして、KSampler 一定でも 何が出てくるのか 掘り出し物画像が出てくるのが楽しいですね。
SD1.5の面白味です。

CLIP Set Last Layerは、Flux1系のSchnellでも用いられます。