ComfyUI.Tokyo
SD1.5 lora VAE
VAE(vae-ft-mse-840000-ema-pruned.safetensors)とLoRA(more_details.safetensors)は、それぞれ異なる役割と特徴を持っています。
VAE(Variational AutoEncoder)の役割と特徴
ComfyUIにおけるVAEは、基本的に以下の役割を担います。
画像のエンコードとデコード:
- 画像をピクセル空間(私たちが目にする通常の画像)と潜在空間(AIが画像を扱うための抽象的なデータ表現)の間で変換します。
- エンコード: 高解像度の画像データをAIが扱いやすい低次元の潜在表現に圧縮します。
- デコード: 生成された潜在表現から、最終的なピクセル画像へと復元します。
生成プロセスの最終段階:
- Text-to-Imageの生成プロセスでは、VAEは通常、最後のステップで使われます。
- KSamplerノードなどで潜在空間で生成された画像を、最終的に視覚化可能なピクセル画像に変換するために使用されます。
画質の調整:
- VAEの種類や設定によって、生成される画像の色彩、コントラスト、鮮明さなどに影響を与えます。
- vae-ft-mse-840000-ema-pruned.safetensorsのようなVAEは、一般的に高品質な画像生成のために調整されており、特に色彩の再現性やディテールの表現に寄与します。
LoRA(Low-Rank Adaptation of Large Language Models)の役割と特徴
LoRAは、 Stable Diffusionモデルの「フィルター」や「アドオン」のようなものと考えると理解しやすいです。
特定のスタイル、コンテンツ、細部の追加:
- AIモデル全体の重みを大きく変更することなく、特定の要素(キャラクター、画風、オブジェクトなど)を学習させ、生成画像に反映させます。
- 例えば、特定のアートスタイル(水墨画など)を適用したり、特定のキャラクターの特徴を追加したりできます。
ファイルサイズが小さい:
- LoRAは、元の基盤モデル(Stable Diffusion 1.5など)に比べて非常にファイルサイズが小さいのが特徴です。これにより、多数のLoRAを容易に管理・切り替えることができます。
柔軟な適用と組み合わせ:
- 複数のLoRAを同時に適用することも可能で、これによりさらに複雑な表現や多様なスタイルの画像を生成できます。
- ComfyUIでは、LoRAノードを使ってStrength(強度)を調整することで、そのLoRAの効果の度合いを細かく制御できます。
more_details.safetensorsの具体的な役割と特徴:
- more_details.safetensorsという名前が示す通り、このLoRAは一般的に生成される画像の細部の向上に特化しています。
- 具体的には、以下のような効果が期待されます。
- ディテールの増加: 画像の細かな部分(髪の毛、衣服のシワ、背景のテクスチャなど)がより鮮明に、かつ豊富に表現されます。
- 画質の向上: 全体的な画像のシャープさや解像感が向上し、より高品質なイラストや写真に近い生成物を得られることがあります。
- 目の表現の改善: 特にキャラクターの目など、表現が難しい部分のクオリティを上げることが知られています。
- ノイズの軽減: 生成される画像の粒状ノイズを軽減し、より滑らかな表現にする効果を持つ場合もあります。
- このLoRAは、プロンプトに特定の「トリガーワード」を記載することで、その効果をより強く引き出すことができる場合がありますが、more_detailsのような汎用的なLoRAではトリガーワードが不要なことも多いです。
まとめると、VAEは生成された潜在データを視覚的な画像に変換し、その画質全般に影響を与える基盤的な役割を担う一方、LoRA(特にmore_details.safetensorsのようなもの)は、基盤モデルの能力を補完し、特定の側面(この場合は画像の細部や情報量)を強化するための追加的な学習データとして機能します。
Workflowの出展元 OpenArt Workflows
Workflow
LoRAの接続の仕方は、Checkpointとプロンプトの間に縦続接続する格好となります。
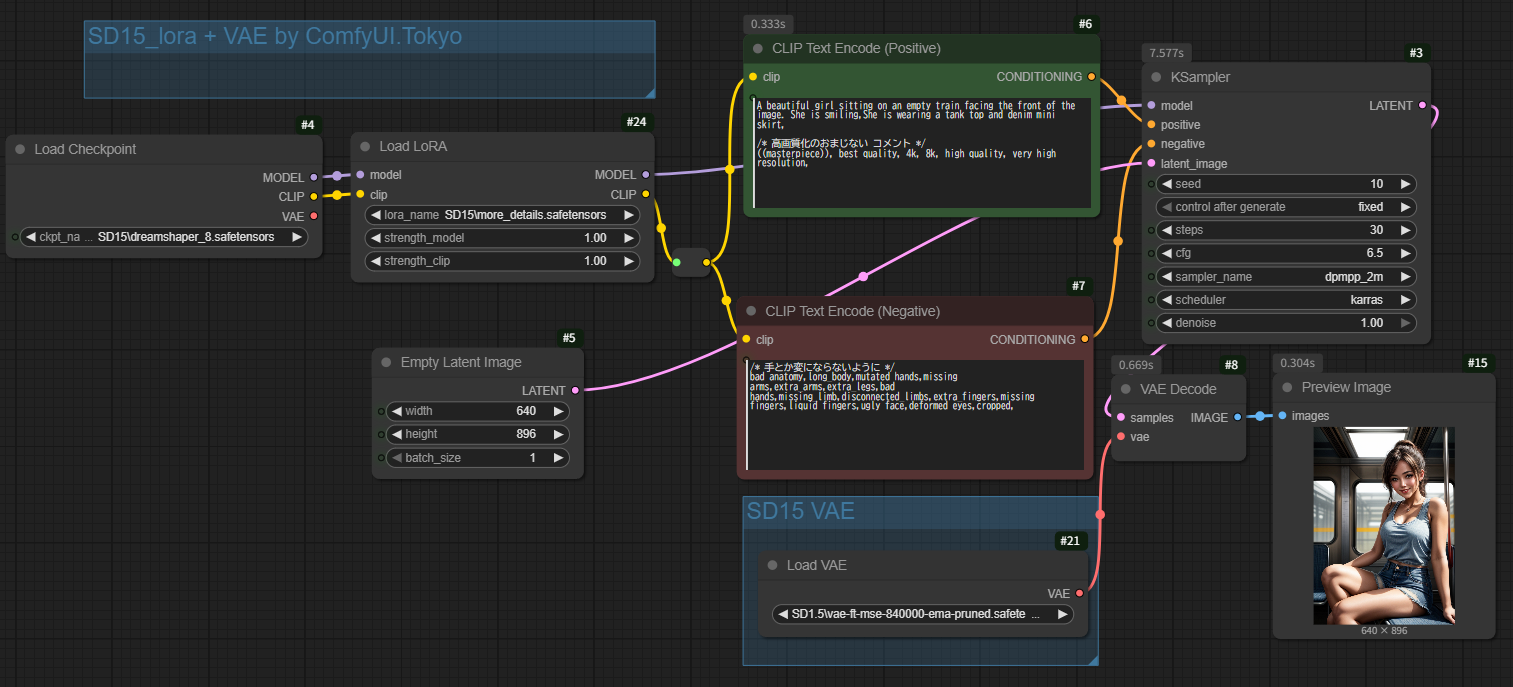

ちょっと画像を小さくして生成してみます。
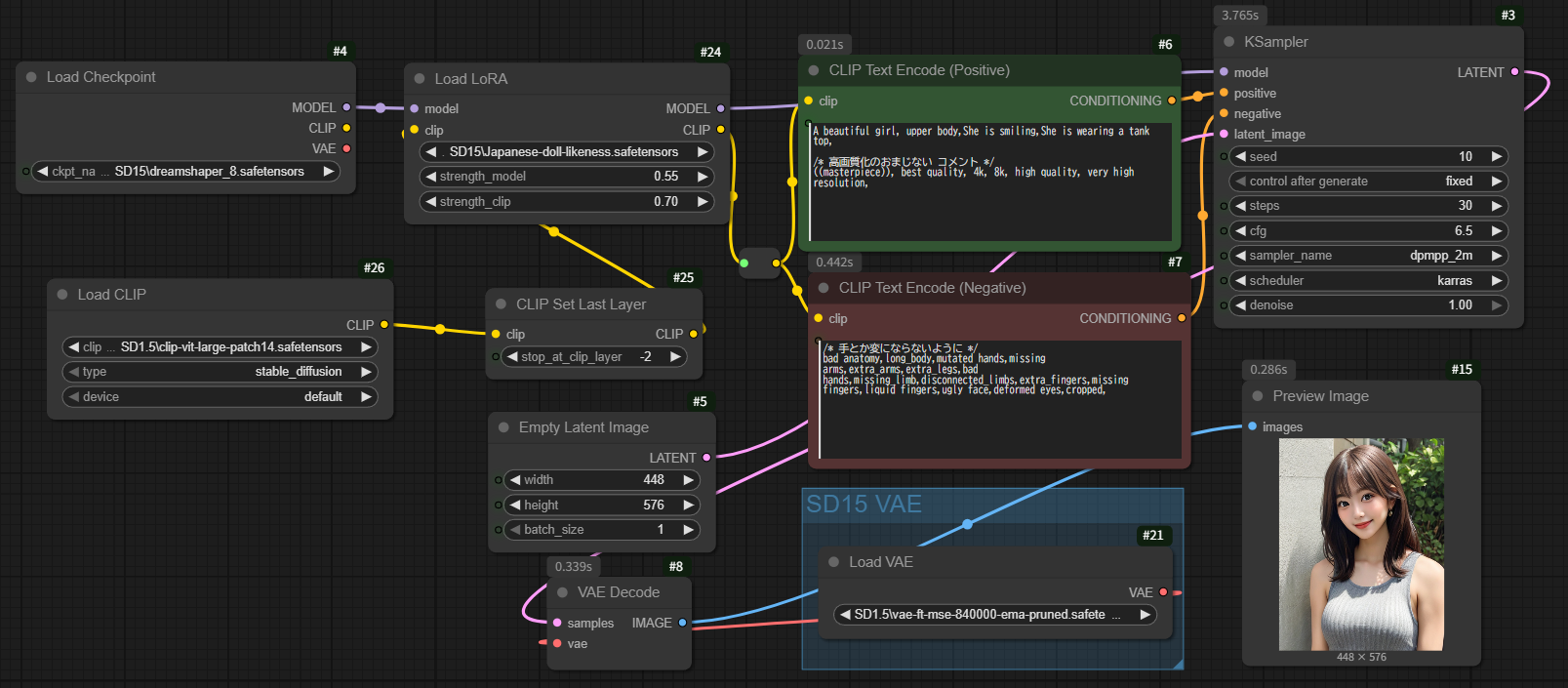
Checkpoint DreamShaper_8
Workflow
loraなし

loraあり
