ComfyUI.Tokyo
SD15_Outpaint_with_Inpaint
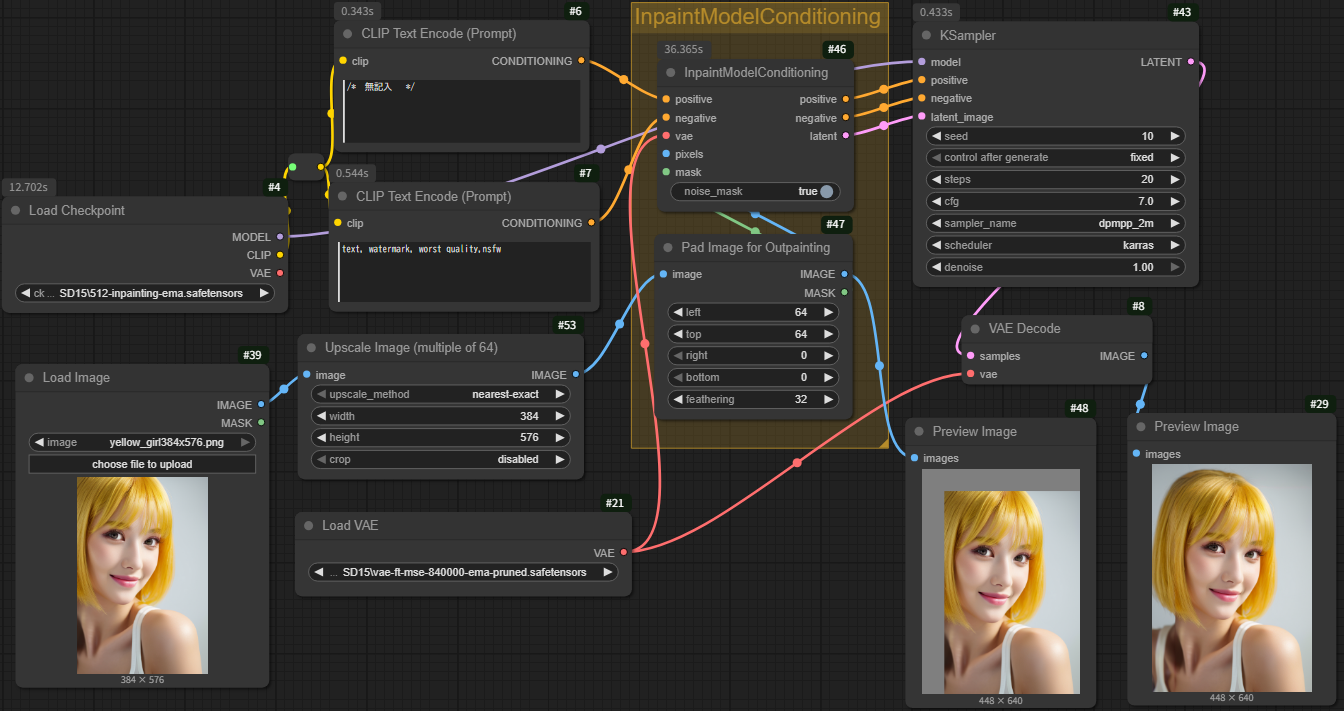
ComfyUIのワークフローJSONファイル(`SD15 _Outpaint_with_inpaint.json`)は、既存の画像を拡張する「アウトペイント(Outpainting)」の手法を示します。これはInpaintingの原理を応用したもので、画像の外部に新しいコンテンツを生成します。
アウトペイントの原理
アウトペイントは、Inpaintingが「マスクされた領域を埋める」のに対し、「マスクによって元の画像の外側に空白を作り出し、その空白をAIに埋めさせる」ことで画像を拡張します。 このワークフローの基本的な流れは以下の通りです。- 入力画像の準備:
- 拡張したい元の画像を用意します(例: `yellow_girl384x576.png`)。
- 画像のパディングとマスクの作成:
- `ImagePadForOutpaint` ノードが中心的な役割を果たします。このノードは、元の画像の上下左右に「パディング(余白)」を追加します。
- このパディングされた領域が、AIが新しく生成する「空白」となります。同時に、このノードは元の画像部分を黒く、パディングされた空白部分を白くするマスクを自動的に作成します。このマスクは、AIに「白い領域を生成する」という指示を与えます。
- プロンプトとモデルの準備:
- 拡張したい内容を指示するプロンプトと、Inpainting/Outpaintingに適したモデル(`512-inpainting-ema.safetensors`)をロードします。
- 潜在空間での処理:
- 元画像(パディングされたもの)と、新しく生成されたマスクが、VAEによって潜在空間に変換されます。
- `InpaintModelConditioning` ノードが、プロンプト、モデル、パディングされた画像、マスクを受け取り、ノイズを加える範囲(マスクされた領域)や、ノイズ除去の際の条件を調整します。
- ノイズ除去(画像生成):
- `KSampler` ノードが、`InpaintModelConditioning` からの指示に基づき、パディングされた空白領域に新しい画像を生成します。この際、元の画像の内容と矛盾しないように、AIが周囲のコンテキストを考慮して内容を生成します。
- 画像のデコードと出力:
- 生成された潜在画像がVAEによってピクセル画像にデコードされ、元の画像が拡張された最終的な画像が得られます。
ワークフローの解説
主要なノードとそれらの連携について具体的に解説します。
- LoadImage (ID: 39):
- `yellow_girl384x576.png` という元の画像をロードします。この画像が拡張の基点となります。
- CheckpointLoaderSimple (ID: 4):
- `SD15\512-inpainting-ema.safetensors` をロードします。これは、Inpainting(そしてOutpainting)に特化したStable Diffusion 1.5のチェックポイントモデルです。このようなモデルは、画像の欠損部分を自然に埋めたり、画像をシームレスに拡張したりする能力に優れています。
- VAELoader (ID: 21):
- `SD15\vae-ft-mse-840000-ema-pruned.safetensors` をロードします。高品質なVAEであり、画像の潜在空間へのエンコードとピクセル空間へのデコードを担い、最終的な画質に貢献します。
- Reroute (ID: 54):
- `CheckpointLoaderSimple` からのCLIPモデル出力を、ポジティブプロンプトとネガティブプロンプトの`CLIPTextEncode` ノードに分配するためのユーティリティノードです。
- CLIPTextEncode (Positive Prompt) (ID: 6):
- テキスト: `*/ 無記入 */` (Empty prompt)
- このアウトペイントのワークフローでは、ポジティブプロンプトを空にしています。これは、AIに「元の画像のスタイルや内容を維持しつつ、自然に拡張してほしい」という指示を暗に与えるためです。特定の要素を追加するのではなく、既存の画像を「続ける」ことを意図しています。
- CLIPTextEncode (Negative Prompt) (ID: 7):
- テキスト: `text, watermark, worst quality, nsfw` 生成される画像に望ましくない要素(テキスト、透かし、低品質、不適切な内容)が含まれないようにするためのネガティブプロンプトです。
- ImageScale (ID: 53) - "Upscale Image (multiple of 64)":
- 入力された画像(`yellow_girl384x576.png`)を`nearest-exact`メソッドで、指定された幅(384)と高さ(576)にスケール変更します。これは、次の`ImagePadForOutpaint`ノードで適切なパディングを適用するために、画像サイズを調整するステップです。Stable Diffusionのモデルは、特定のサイズ(例えば、512x512や768x768など)や、64の倍数のサイズで学習されていることが多いため、それに合わせて画像をリサイズすることが重要です。
- ImagePadForOutpaint (ID: 47):
- 入力画像にパディングを追加します。
- `left`: 64ピクセル
- `top`: 64ピクセル
- `right`: 0ピクセル
- `bottom`: 0ピクセル
- `feathering`: 32ピクセル (境界のぼかし)
- これにより、元の画像の左と上側に64ピクセルずつ空白が追加され、画像が拡張されます。`feathering`は、元の画像と新しく生成される領域の境界を滑らかに繋ぐためのぼかしの幅を指定します。
- 出力として、パディングされた画像と、新しい空白領域を示すマスク(白い部分が空白領域)を生成します。
- 入力画像にパディングを追加します。
- InpaintModelConditioning (ID: 46):
- ポジティブ/ネガティブプロンプト、VAE、`ImagePadForOutpaint`から受け取ったパディング済み画像とマスクを組み合わせます。
- `noise_mask` が `true` に設定されています。これは、マスクされた領域(新しく追加された空白部分)にのみノイズを加え、元の画像部分の情報を保持するようにAIに指示します。これにより、元の画像は維持されたまま、空白部分だけが生成されます。
- KSampler (ID: 43):
- `InpaintModelConditioning` からの条件付け情報に基づき、パディングされた画像(ノイズが加えられた空白領域)からノイズを除去し、新しいコンテンツを生成します。
- `denoise` が `1` に設定されており、マスクされた領域(パディングされた部分)を完全に新しい内容で埋めることを意味します。
- `sampler_name`: `dpmpp_2m`、`scheduler`: `karras` は、画像生成に使用されるサンプラーとスケジューラーのアルゴリズムであり、生成される画像の品質や特性に影響します。
- VAEDecode (ID: 8):
- `KSampler` で生成された潜在画像を、最終的なピクセル画像に変換します。
- PreviewImage (ID: 48, 29):
- 途中のパディングされた画像(`ImagePadForOutpaint`の出力)と、最終的に生成されたアウトペイント後の画像を表示します。
アウトペイントの特徴
- 画像のシームレスな拡張: Inpaintingモデルと`ImagePadForOutpaint`ノードの組み合わせにより、元の画像のスタイル、色、内容を保ちながら、左右上下に自然に画像を拡張できます。
- コンテキストの利用: AIは元の画像の周囲のコンテキスト(例えば、背景、人物の向きなど)を理解し、それに合わせて新しい内容を生成するため、拡張された部分が元の画像と調和します。
- クリエイティブな自由度: プロンプトを調整することで、拡張部分に特定の要素(例:草原に花を追加、空に雲を追加など)を生成させることも可能です。今回のワークフローのように空のプロンプトでは、既存の背景の続きを生成する傾向が強くなります。
- 用途の多様性: 写真のトリミング不足の修正、壁紙やバナー画像の作成、アートワークの拡張など、様々なクリエイティブな用途に活用できます。
- `feathering` パラメータの重要性: `ImagePadForOutpaint` の `feathering`(羽根ぼかし)設定は、元の画像と新しく生成される領域の境界をどれだけ滑らかにするかを決定します。適切なフェザリングにより、継ぎ目のない自然なアウトペイントが可能になります。
このワークフローは、既存の画像を「トリミング解除」したり、より広いキャンバスに再配置したりする際に非常に強力なツールとなります。
Workflow
SD15_Outpaint_with_inpaint.json

【384(64×6) × 576(64×9)】

【384+64=448、576+64=640】

【結果】
もう一つのworkflow
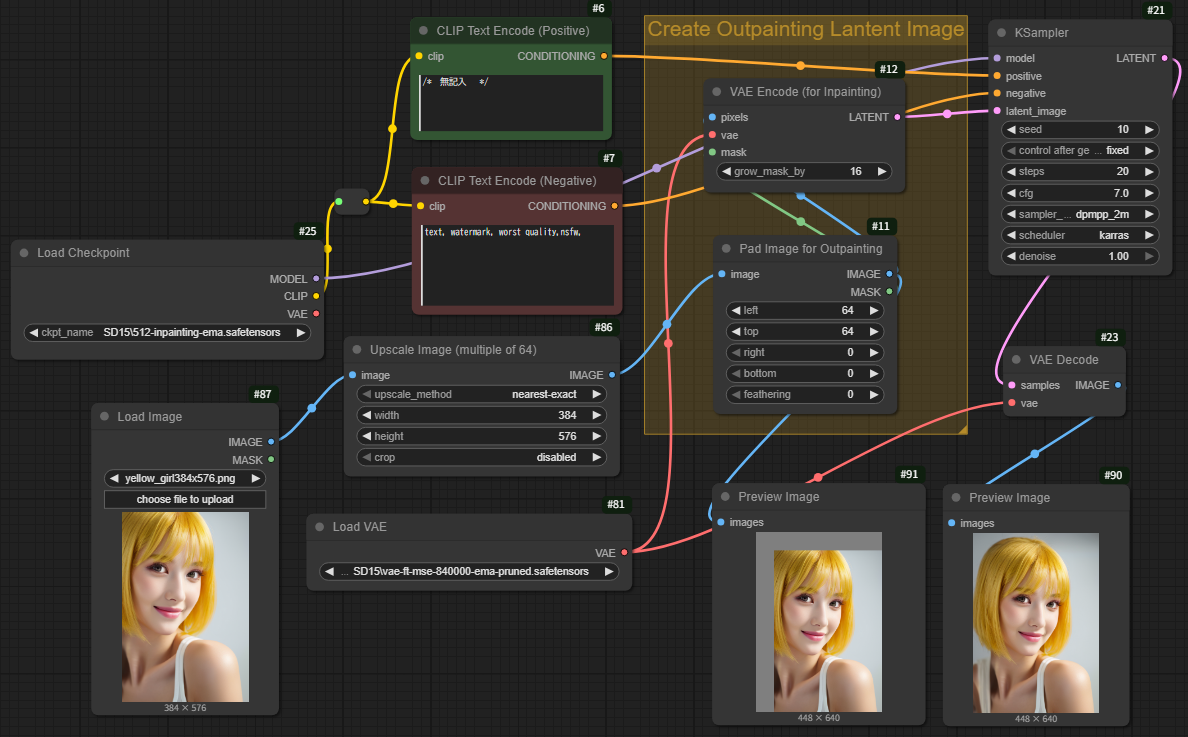
Workflow
SD15_Outpaint_with_inpaint2.json
上のOutpaintingのワークフローで、`InpaintModelConditioning`ノードの代わりに`VAE Encode (for Inpainting)`ノード(`grow_mask_by 16`設定)を使用しても同様の成果が得られました。
この2つのノードの違いと、`VAE Encode (for Inpainting) grow_mask_by 16`の機能について簡単に解説します。
VAE Encode (for Inpainting) ノードの機能
`VAE Encode (for Inpainting)`ノードは、Inpainting(またはOutpainting)の際に、元の画像とマスクをVAE(Variational AutoEncoder)によって潜在空間にエンコードする機能を持つノードです。
- 画像のエンコード: 入力された画像(元の画像)を、AIが扱いやすい潜在表現に変換します。
- マスクの処理とノイズの追加:
- このノードは、入力されたマスクに基づいて、エンコードされた潜在画像にノイズを追加します。具体的には、マスクで示された領域(白く塗られた領域、つまり生成してほしい空白部分や削除したいオブジェクト部分)に、ランダムなノイズを付加します。これにより、AIはその領域を自由に生成できるようになります。
- `grow_mask_by` パラメータは、入力されたマスクの境界を外側に拡張するピクセル数を指定します。`grow_mask_by 16`の場合、マスクが16ピクセル分外側に拡張されます。
`grow_mask_by 16` の役割
この`grow_mask_by 16`という設定は、InpaintingやOutpaintingの品質を向上させる上で非常に重要です。
- 境界のブレンディング(融合): マスクを少し広げることで、AIは元の画像と新しく生成される領域の境界部分を、より広い範囲で考慮して生成することができます。これにより、生成されたコンテンツが元の画像に自然に溶け込みやすくなり、継ぎ目や不自然な線が残りにくくなります。
- 「マスクの跡」の解消: マスクが厳密すぎると、AIが境界部分で情報をうまく繋げず、結果として「マスクの跡」のようなものが残ることがあります。マスクを少し拡張することで、この問題を軽減し、よりシームレスな結果が得られます。
`InpaintModelConditioning` ノードとの違い
両ノードはInpainting/Outpaintingワークフローにおいて類似の目的を果たしますが、その内部的な処理や柔軟性には違いがあります。
- 主な役割と処理の重点:
- `VAE Encode (for Inpainting)`: 主に画像とマスクの潜在空間へのエンコード、およびマスク領域へのノイズ付加に焦点を当てています。つまり、Inpaintingプロセスにおける「初期状態の潜在画像」を準備する役割が強いです。
- `InpaintModelConditioning`: 画像とマスクのエンコードに加えて、プロンプト(ポジティブ/ネガティブコンディショニング)の調整を行います。このノードは、マスク情報を使って、AIモデルが画像を生成する際の「条件付け」をより精密に行うことができます。特に、マスクされていない領域の情報をより強く維持し、マスクされた領域にプロンプトの内容を反映させるための調整を行います。また、`noise_mask`パラメーターでノイズをマスク領域に限定するかどうかを制御できます。
- マスクの処理方法:
- `VAE Encode (for Inpainting)`: `grow_mask_by`パラメータによって、ノード内部でマスクの拡張とそれに伴うノイズ付加をシンプルに行います。
- `InpaintModelConditioning`: このノード自体には`grow_mask_by`のようなマスク拡張機能は直接ありません。代わりに、別途`GrowMask`や`ImpactGaussianBlurMask`などのノードを使って事前にマスクを処理し、その結果を`InpaintModelConditioning`に渡すことで、より複雑で精密なマスク処理(例:複数段階のぼかしなど)を実現できます。これにより、ユーザーはマスクの処理方法をより細かく制御できます。
- 柔軟性と制御性:
- `VAE Encode (for Inpainting)`: よりシンプルで、基本的なInpainting/Outpaintingのユースケースに適しています。少ないノードでワークフローを構築できます。
- `InpaintModelConditioning`: マスクの事前処理とコンディショニングの調整という点で、より高度な制御が可能です。特に、マスク境界の馴染み方を細かく調整したい場合や、複雑なマスク処理をワークフローに組み込みたい場合に有利です。
なぜ同様の成果が得らるのか?
今回のOutpaintingのケースで同様の成果が得られたのは、以下のような要因が考えられます。
- マスクのシンプルさ: アウトペイントの場合、マスク領域(空白部分)は比較的シンプルな形状であることが多いです。`VAE Encode (for Inpainting)`の`grow_mask_by 16`というシンプルなマスク拡張が、その目的を十分に果たしました。
- Inpainting特化モデルの性能: 使用しているモデル(`512-inpainting-ema.safetensors`)自体が、マスクの境界を自然に処理する能力に非常に優れているため、マスクの調整が多少シンプルでも良い結果が得られやすいです。
- プロンプトの性質: Outpaintingでプロンプトが空の場合、AIは主に元の画像のコンテキストを参考に生成します。この場合、`InpaintModelConditioning`が行うようなプロンプトの精密な条件付けが、そこまで大きな差を生み出さなかった可能性があります。
結論として、`VAE Encode (for Inpainting) grow_mask_by 16`は、Inpainting/Outpaintingにおける「マスク領域へのノイズ付加と境界の簡単なブレンディング」を簡潔に実行するノードです。
一方、`InpaintModelConditioning`は、より高度なマスク処理の連携と、プロンプト条件付けの精密な調整を可能にし、複雑なシナリオや最高品質を追求する際にその真価を発揮します。
シンプルで自然な結果が得られる場合は、`VAE Encode (for Inpainting)`で十分なことが多いです。