ComfyUI.Tokyo
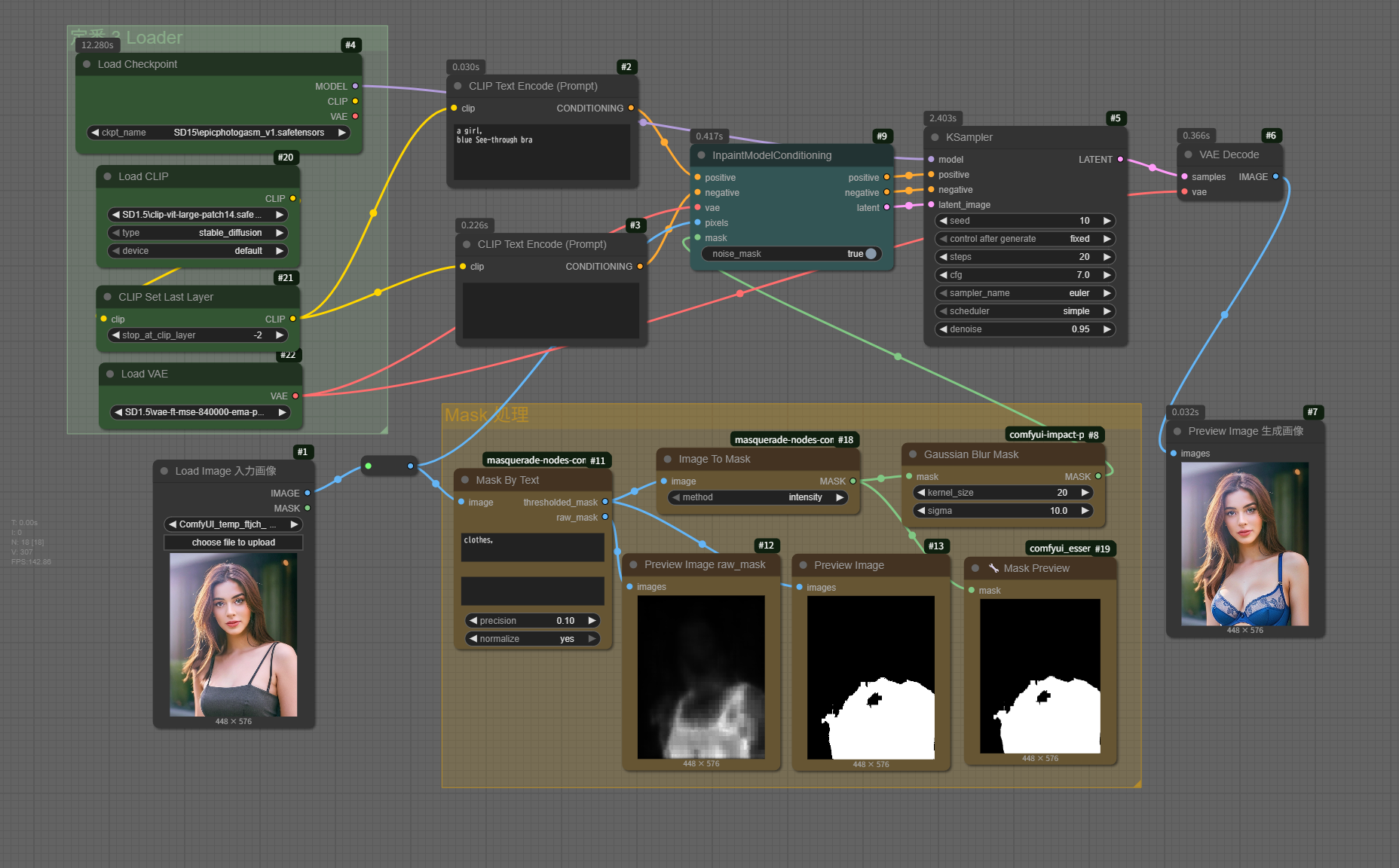
SD15_InpaintModelConditioning_Segmentation Mask処理によるインペイント
ComfyUIにおけるSD1.5のインペイント処理において、`InpaintModelConditioning`ノードと`Mask By Text`ノードを組み合わせる場合、`Mask By Text`ノードは非常に強力な機能を提供します。
その特徴を以下に説明します。
Mask By Textノードの主な特徴(ComfyUI SD1.5)
`Mask By Text`ノードは、その名の通り、入力されたテキストプロンプトに基づいてマスクを生成するノードです。これは従来のインペイントにおける手動マスク作成や、特定の形状に基づいたマスク作成と比較して、以下の点で特徴的です。
- テキストによる直感的で柔軟なマスク生成:
- キーワード指定: 画像内でインペイントしたい対象をテキストで記述するだけで、その対象の領域を自動的にマスクとして検出・生成します。
例えば、「sky」「tree」「car」「face」といった具体的なオブジェクトや、「blurred background」のような抽象的な概念でも機能する可能性があります。 - 修正の効率化: 手動で複雑な形状をマスクする手間を省き、試行錯誤のプロセスを大幅に効率化します。
- セマンティックな理解に基づくマスク:
- `Mask By Text`ノードは、基盤となる画像認識モデル(多くの場合、CLIPのようなモデル)を活用して、入力されたテキストと画像内容の関連性を理解しようとします。
これにより、単なるピクセル値ではなく、画像内の「意味」に基づいてマスクを生成することが可能です。 - 例えば、「山」と指定すれば山岳地帯全体を、「人物」と指定すれば画像内の人物全体をマスクとして認識する、といった高度な処理が期待できます。
- 細かい制御と調整(可能な場合):
- ノードの実装にもよりますが、生成されるマスクの閾値やぼかし、拡張/収縮などのパラメータが提供される場合があります。
これにより、テキストで生成されたマスクをさらに微調整し、より正確なインペイント領域を指定することが可能になります。 - 例えば、マスクが広すぎる場合に収縮させたり、エッジが鋭すぎる場合にぼかしたりすることができます。
- InpaintModelConditioningとの強力な連携:
- `InpaintModelConditioning`ノードは、生成されたマスクと元画像を元に、インペイントのための条件付け情報(latent spaceでのマスク情報など)を作成します。
- `Mask By Text`が生成したセマンティックなマスクを`InpaintModelConditioning`に渡すことで、Stable Diffusionモデルは「この領域を、このテキストプロンプトで指定された内容で変更する」という指示をより正確に受け取ることができます。
これにより、より自然で意図通りのインペイント結果を得やすくなります。
注意点と考慮事項
- テキストの精度: 生成されるマスクの品質は、入力するテキストプロンプトの具体性や、基盤となるモデルの認識能力に大きく依存します。
あいまいな表現や、モデルが学習していない概念では、期待通りのマスクが生成されない場合があります。 - モデルの限界: `Mask By Text`が利用する画像認識モデルも万能ではありません。複雑なシーンや、認識が難しいオブジェクトに対しては、手動での調整や他のマスク生成方法との組み合わせが必要になることがあります。
- 計算コスト: テキストからセマンティックなマスクを生成する処理は、ある程度の計算リソースを必要とする場合があります。
まとめると、`Mask By Text`ノードはComfyUIのSD1.5インペイントにおいて、テキストベースで直感的かつセマンティックなマスク生成を可能にし、`InpaintModelConditioning`ノードとの組み合わせにより、非常に効率的で高品質なインペイント処理を実現する強力なツールと言えます。
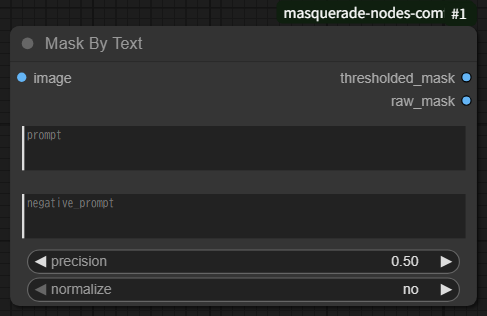
Mask By Textノードの入出力部(ComfyUI SD1.5)
「Mask By Text」ノードは、画像とテキストプロンプトを使って、対象領域のマスクを自動生成する強力なツールです。ClipSegというモデルを活用して、自然言語から意味的な領域を抽出します。
入力パラメータの特徴
以下の情報を入力することで、マスク生成の精度や対象を細かく制御できます:- image:マスクを生成する元画像。
- prompt:抽出したい領域を記述するテキスト。複数指定する場合は `|` で区切ります。
- negative_prompt:除外したい領域を記述するテキスト。こちらも `|` で複数指定可能。
- precision:マスクの精度(0.0〜1.0)。高いほど厳密なマスクになります。
- normalize:結果を画像全体で正規化するかどうか(Yes/No)。モデルの認識が不安定な場合に有効です。
出力パラメータの特徴
生成されたマスクは、以下の形式で出力されます:- Thresholded Mask:精度と正規化を考慮した最終マスク。
- Raw ClipSeg Results:ClipSegの生データ(0.0〜1.0のスコア)。複雑な処理や比較に活用可能。
補足Tips
- 複数のプロンプトやネガティブプロンプトを1つのノードで扱うことで、処理効率が向上します。
- より複雑なマスク処理には「Combine Masks」ノード(UnionやDifference)との併用が便利です。
このノードは、インペイント処理や構図の調整、特定領域の強調など、AIアート制作において非常に柔軟な表現を可能にします。
workflow
SD15_InpaintModelConditioning_Segmentation.json