ComfyUI.Tokyo
SD15_InpaintModelConditioning 一番簡単なインペイント
inpaint の実現は主に三つの方法があります。
| inpaint手法 | 役割 |
|---|---|
| VAE Encode (for inpainting) | マスク付き画像を latent space に変換 |
| SetLatentNoiseMask | マスク領域にノイズを注入し、再生成対象を明示 |
| InpaintModelConditioning | マスク情報と元画像の文脈を使って、生成内容を制御 |
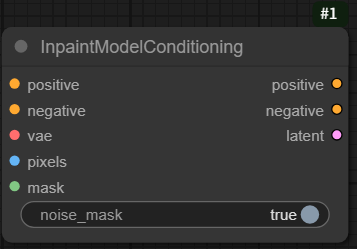
InpaintModelConditioning は、Stable Diffusion 1.5(SD1.5)での inpainting(画像の一部を補完・再生成する処理)において、マスクされた領域に対して適切な生成を行うための条件付け(conditioning)を行うステップです。
以下にその特徴を解説します。
InpaintModelConditioning の特徴
- マスク情報を活用した条件付け
- マスクされた領域(再生成したい部分)と、元画像の未マスク領域(保持したい部分)を区別して処理。
- モデルは「どこを再生成すべきか」「どこを保持すべきか」を理解するために、マスク情報を条件として受け取る。
- 元画像の文脈を保持
- 未マスク領域の情報を使って、マスク領域に自然な補完を行う。
- たとえば、顔の一部がマスクされている場合、残りの顔の特徴を参考にして、違和感のない補完を行う。
- テキストプロンプトとの融合
- テキストプロンプト(例:「青い空を背景にした女性」)とマスク情報の両方を使って、生成内容を制御。
- これにより、マスク領域に対してプロンプトに沿った内容を生成できる。
- 特殊なモデルアーキテクチャ
- 通常のテキスト条件付き生成とは異なり、inpainting用に訓練されたモデル(通常は inpainting suffix が付いた checkpoint)を使用。
- このモデルは、マスク情報を追加の入力として受け取るように設計されている。
応用例
- 顔の一部を修復(例:目だけを再生成)
- 背景の変更(例:建物の一部を空に置き換える)
- オブジェクトの削除・追加(例:人物の隣に動物を追加)
workflow
SD15_InpaintModelConditioning.json
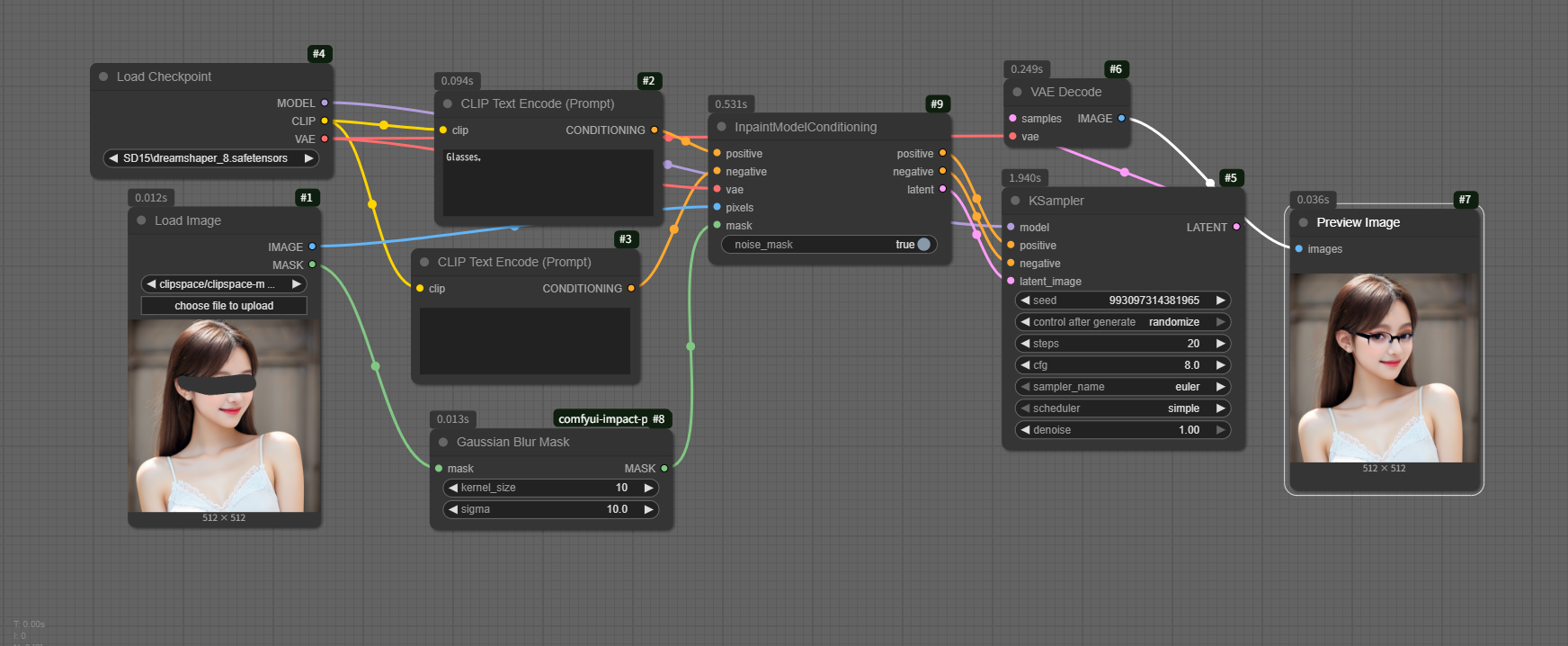



目の向きが変わってしまいました。