ComfyUI.Tokyo
SD15_Florence2Run: Florence2Runによるインペイント
ComfyUIのFlorence2Runノードは、MicrosoftのFlorence-2モデルを活用して、画像と言語の処理を行う強力なノードです。以下にその概要と使い方をまとめました。
Florence2Runノードとは?
Florence2Runは、画像とテキスト入力を使って、以下のような視覚と言語の統合タスクを実行できます:
- 画像キャプション生成(caption, detailed_caption, more_detailed_caption)
- 物体検出(region_caption, dense_region_caption)
- 領域提案(region_proposal)
- OCR(文字認識)(ocr, ocr_with_region)
- セグメンテーション(referring_expression_segmentation)
- 文書質問応答(DocVQA):画像内の文書に対して質問し、回答を得る
使用するモデル:Florence-2
Florence2Runノードは、Microsoftが開発したFlorence-2モデルを使用します。これは、126万枚の画像に対して54億件のアノテーションを含むFLD-5Bデータセットで学習された、非常に高性能な視覚基盤モデルです。
利用可能なモデル例:
| モデル名 | 特徴 |
|---|---|
| Florence-2-base | 汎用的な画像と言語処理に対応 |
| Florence-2-large | より高精度な処理が可能 |
| Florence-2-DocVQA | 文書画像に対する質問応答に特化 |
| PromptGenモデル | 画像からプロンプト生成に最適 |
主な入力パラメータ
- `image`: 処理対象の画像
- `text_input`: 一部のタスクで使用するテキストプロンプト(例:DocVQAやセグメンテーション)
- `task`: 実行する処理の種類(例:caption, ocr, region_captionなど)
- `florence2_model`: 使用するFlorence-2モデル
- `fill_mask`: セグメンテーション時にマスクを塗りつぶすかどうか
- `keep_model_loaded`: モデルをVRAMに保持するかどうか(連続処理に便利)
- `num_beams`: 「ビームサーチ」の探索幅を指定するパラメータ.デフォルト値は 3
出力内容
- `out_tensor`: 処理結果の画像テンソル(例:キャプション付き画像)
- `out_mask_tensor`: セグメンテーションマスク
- `out_results`: バウンディングボックス、信頼度、テキストなどの構造化データ
活用例
- SNS投稿画像に自動キャプションを付ける
- 商品画像からタグを抽出してECサイトに活用
- スキャンした領収書から金額や日付を抽出(DocVQA)
- 画像からプロンプトを生成してStable Diffusionに活用
もっと詳しく知りたい場合は、[Florence2Runの公式ドキュメント](https://www.runcomfy.com/comfyui-nodes/ComfyUI-Florence2/Florence2Run)や[GitHubのComfyUI-Florence2リポジトリ](https://github.com/kijai/ComfyUI-Florence2)も参考になります。
custom node
カスタム・マネジャでComfyUI-Florence2設定時、もろもろの細かい設定は自動だったと思います。
workflow
GPUが無くても稼働します。
KSampler使用時、GPUなしでも時間がかかりますが確認稼働を実行できます。
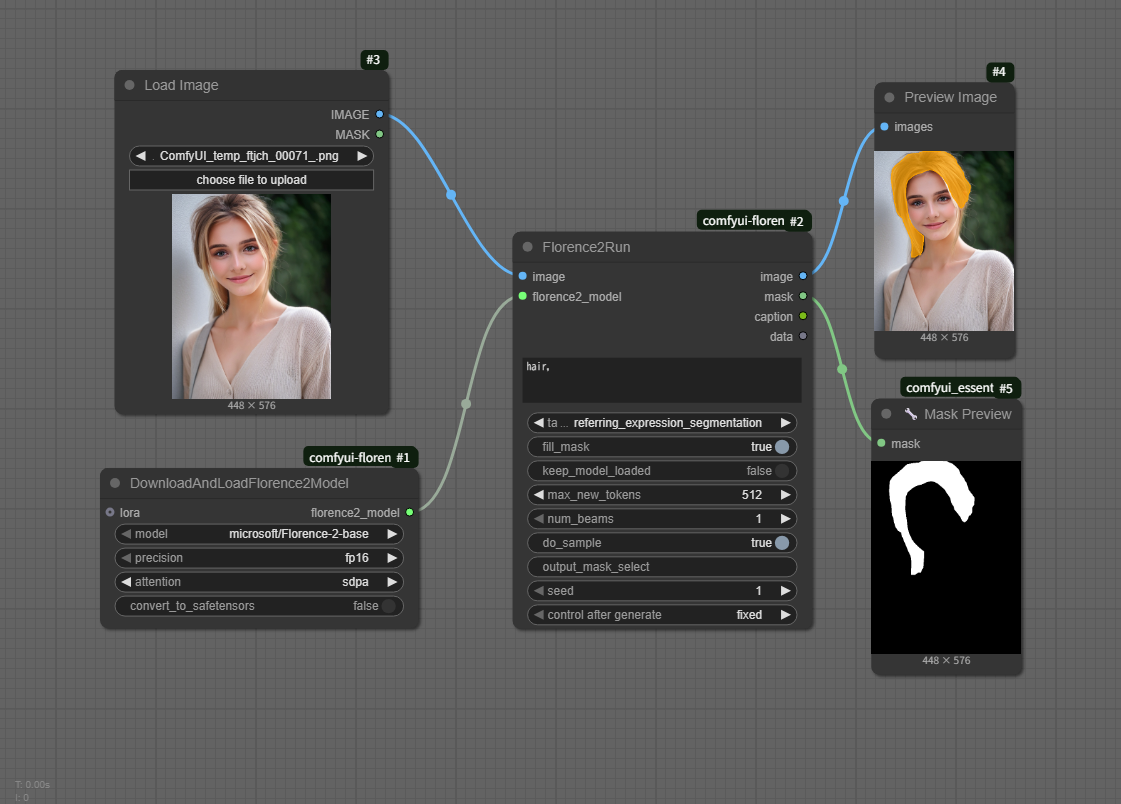



workflow
checkpointは、インペイント系のものを使用します。
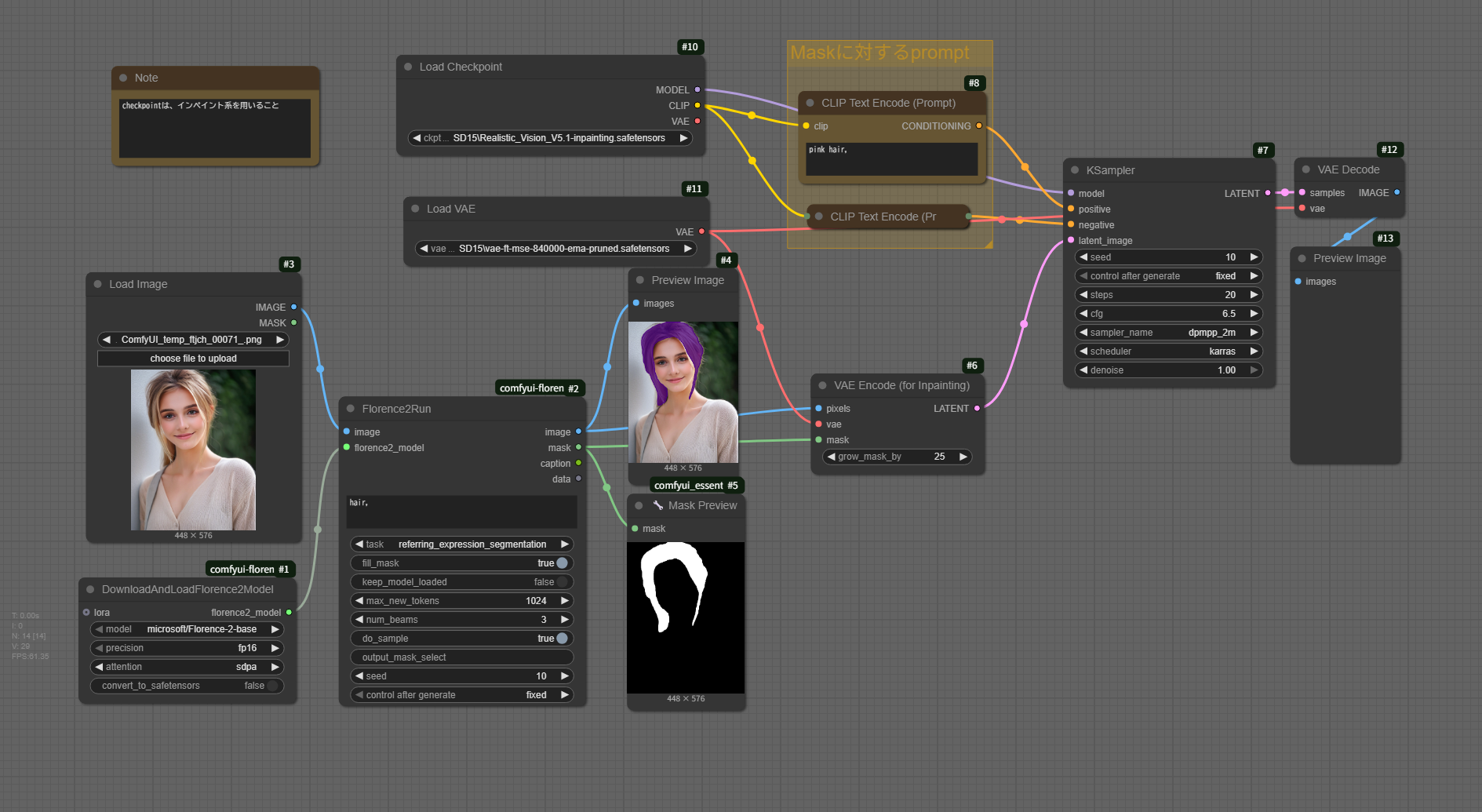



workflow
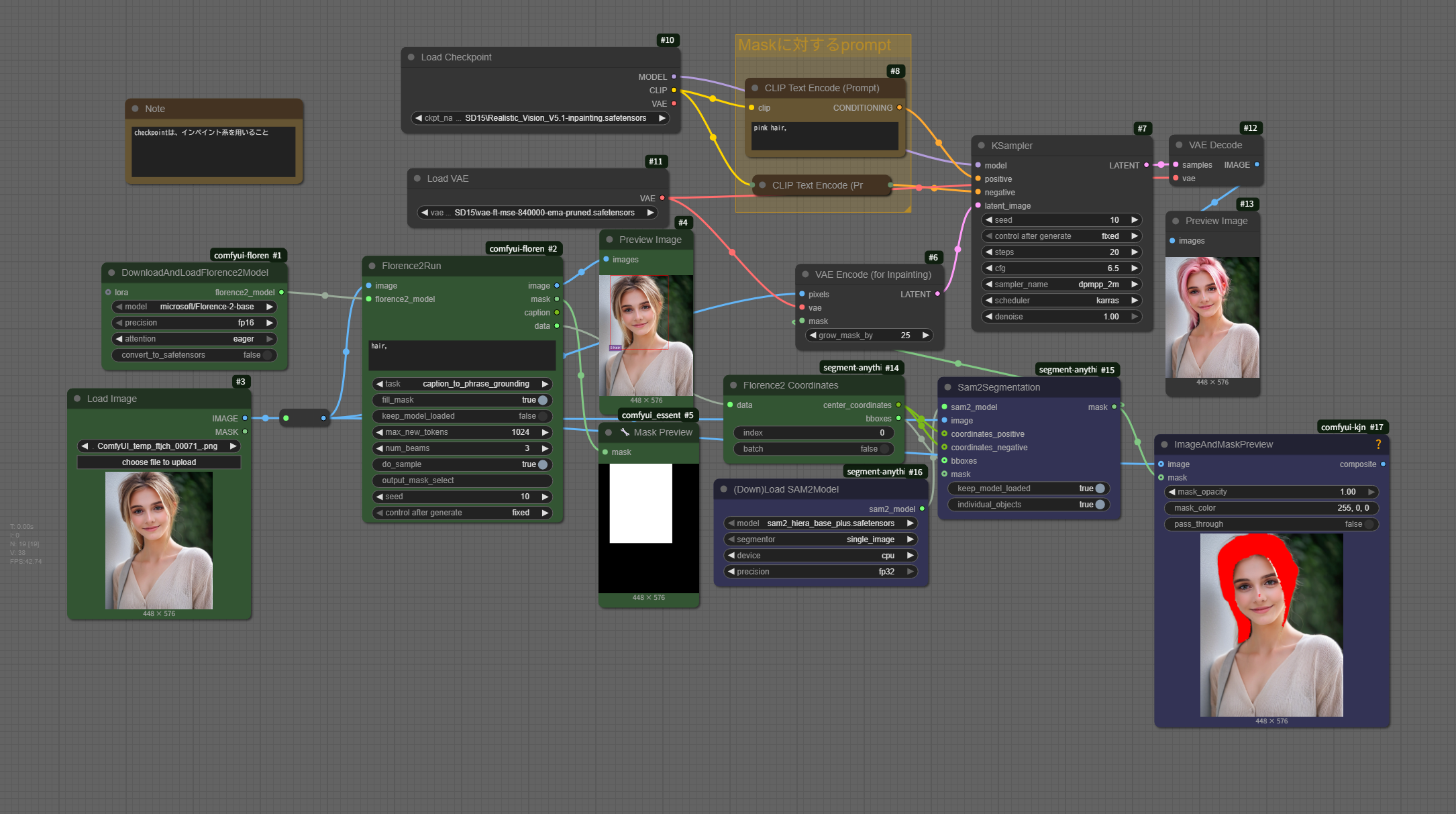



鼻までちいさなMaskがかかってしまっています。
