ComfyUI.Tokyo
SD15_CLIPSeg_Masking インペイント
CLIPSeg Masking ノードは、ComfyUIで画像セグメンテーションを行うための強力なツールで、テキストプロンプトに基づいて画像の特定領域をマスクする処理を簡単に実現できます。
主な特徴
- 自然言語による領域指定 例:「cat」「tree」などの単語で、画像内の対象を自動検出してマスク生成
- 高精度なセグメンテーション Hugging Faceの CIDAS/clipseg-rd64-refined モデルを使用し、細かい領域まで正確にマスク
- インペインティングとの連携 生成されたマスクは、Stable Diffusionなどの画像編集ノードで活用可能(例:背景変更、オブジェクト置換)
clipseg-rd64-refined は、画像セグメンテーションに特化した CLIPSeg モデルの一種で、ComfyUIで使用されるモデルローダー「CLIPSeg Model Loader」で選択可能なオプションのひとつです。
モデルの概要
- 正式名称: CIDAS/clipseg-rd64-refined
- 開発元: ドイツのハイデルベルク大学の研究グループ CIDAS によって開発
- 用途: テキストによる画像セグメンテーション(例:「cat」などの単語で画像内の猫をマスク)
- 特徴:
- rd64 は、ResNet-64ベースのアーキテクチャを意味します
- refined は、より高精度なセグメンテーションが可能なようにファインチューニングされたバージョンであることを示します。
clipseg-rd64-refinedの強み
- 軽量(151Mパラメータ)で高速推論が可能
- Hugging Face Transformersに統合されており、使いやすい
- ゼロショット・ワンショットセグメンテーションに対応
ComfyUIでの使い方
- CLIPSeg Model Loader ノードで clipseg-rd64-refined を選択すると、プロンプト(例:「dog」「tree」など)に基づいて画像の特定領域をマスクすることができます
- 生成されたマスクは、Stable Diffusion の inpainting(画像の一部を描き換える)などに活用できます
使用例
たとえば、画像に「cat」が写っている場合:
- プロンプトに「cat」と入力
- モデルが猫の領域を自動で検出し、マスク画像を生成
- そのマスクを使って、猫を別の動物に置き換えるなどの編集が可能
このモデルは、自然言語による柔軟な領域指定ができるため、画像編集や生成の自由度が高まります。
workflow
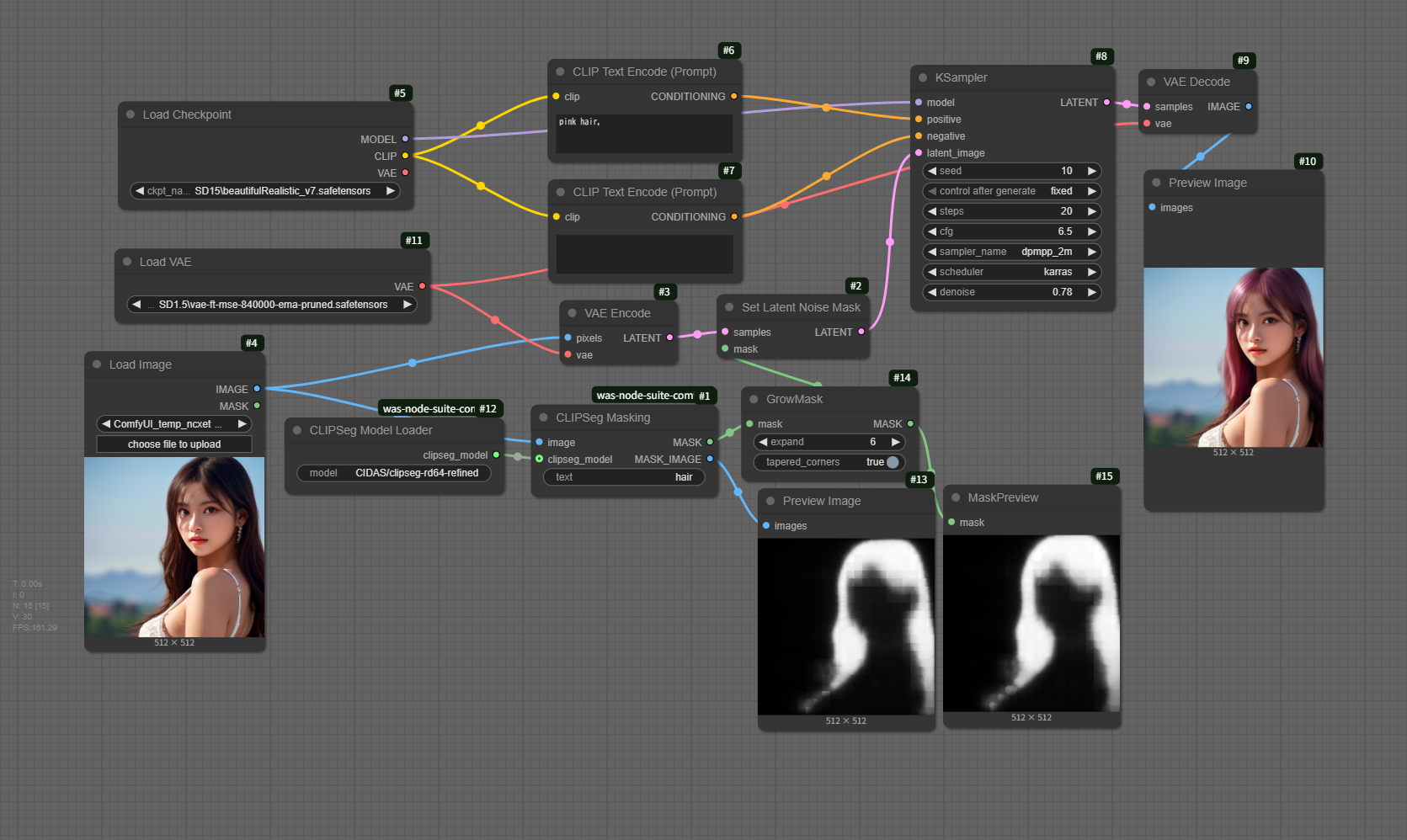
Load image

CLIPSeg Masking

GrowMask

結果

使ってみた感想は、使いにくいインペイントのような気がします。