ComfyUI.Tokyo
複数条件の場合はキーワードの間にスペースを入れてください。例 ksampler controlnet
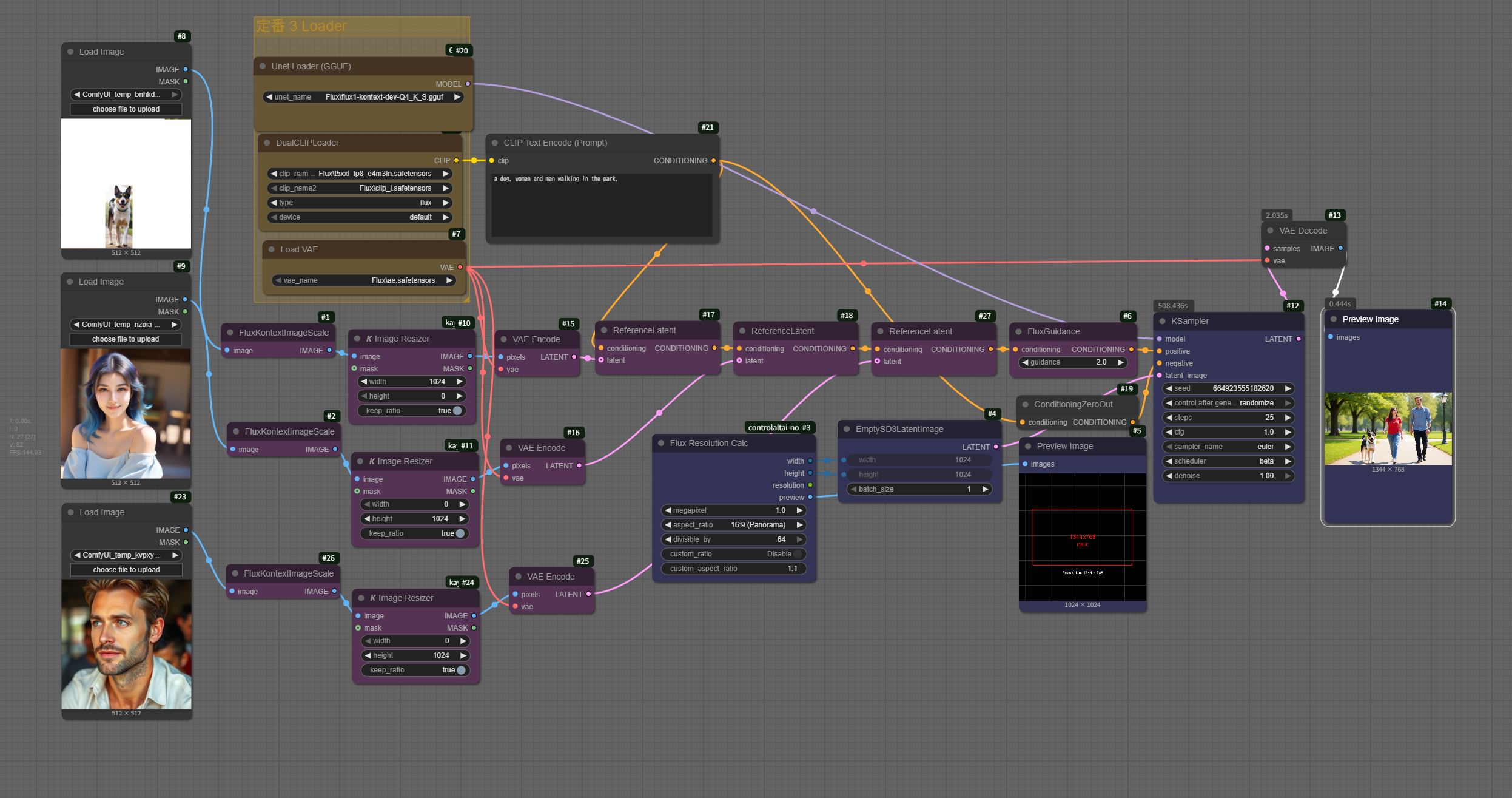
Flux_Kontext_Multiple_Input_Images 多画像の合成
このワークフローのように Flux Kontext に複数の ReferenceLatent を接続 して使う場合、以下の特徴があります。
- Flux Kontext Multiple Input_Images の特徴
- 複数画像からの文脈融合
各画像から抽出した latent 特徴(色・形・質感・構造)を、Flux Kontext が統合して一つの生成コンテキストにします。
例えば- 1枚目 → 背景や構図の情報
- 2枚目 → キャラクターの髪色や服の質感
- 3枚目 → 顔の特徴や肌の質感 といった具合に、役割分担が可能です。
- 優先度は順番や FluxGuidance の数値で制御可能
`ReferenceLatent` を複数接続した場合、後段で接続するものほど「上書き」される傾向があります。
また `FluxGuidance` の数値が高いものほどその画像の影響が強くなります。 - マスク無しでも融合可能 通常の inpaint のようにマスクを必須とせず、全体の特徴をブレンドすることができます。
これにより、マスク作業を省略しつつ複数ソースからの合成ができます。 - ControlNet と異なり抽象的特徴の融合が得意
ControlNet は構造・ポーズなどの明確な制御に特化しますが、Flux Kontext は色合い・質感・雰囲気といった「抽象的」要素の融合に強いです。
- 複数画像からの文脈融合
- このワークフローでの役割例
この例では:- 左上の犬画像 → 背景の一部や動物要素の参照
- 左中の女性画像 → 髪色・服装・雰囲気
- 左下の男性画像 → 顔立ち・肌質
- それらを `ReferenceLatent` で個別に latent 化し、Flux Kontext に渡して統合
- テキストプロンプト(例: "2 dogs, woman and man walking in the park")と融合して生成
- 単一画像 Flux Kontext との違い
| 項目 | 単一画像参照 | 複数画像参照 |
|---|---|---|
| 元画像の忠実度 | 高い(1枚を強く反映) | 分散(複数要素を融合) |
| 特徴の混ざり方 | ほぼそのまま | 部分的・抽象的に混ざる |
| 制御の自由度 | やや低い | 高い(パーツ別の融合が可能) |
| マスク依存度 | 中 | 低(全体融合も自然) |
Workflow
Flux_Kontext_multiple_images.json
Flux_Kontext_multi_2image.json
適当に小さめにしたワンちゃん



Workflowと異なる絵です。
