ComfyUI.Tokyo
複数条件の場合はキーワードの間にスペースを入れてください。例 ksampler controlnet
FluxKontext7 文字の描写
SD1.5のControlNetを用いた方法に比べて、簡単になった理由は、 Flux + Kontext が、これまでの ControlNet 的な「構造の固定」や「マスクの指定」に頼らず、テキスト指示だけで位置やレイアウトを自然に反映できるようになったからです。 原理を分かりやすく説明しますね。- 従来の ControlNet 方式
- ControlNet は 元画像の構造(Canny, Depth, Segmentationなど)を条件として固定します。
- 文字や物体を追加したい場合、
- マスクで編集部分を指定
- 位置を特定して構造情報を供給 が必要でした。
- つまり「どこに描くか」はユーザーが指定しないと AI は分かりません。
- Flux + Kontext のアプローチ
Flux 系モデルは 拡張的な位置・コンテキスト理解 を持っています。 特に Flux Kontext ノードは次のように動きます。- 入力画像を解析
- 背景の構造、余白、空間的配置を理解。
- テキスト指示を条件づけ
- 「左側にネオンサインを追加」など、相対的な位置情報を文脈から推測。
- 全体のレイアウトを再生成
- 新しい要素を自然に埋め込み、既存の背景を保ちながら再描画。
- 「左上に〜」や「右側に〜」と書くだけで位置指定が成立
- 余計なマスクやセグメント処理が不要
- 背景との一体感も自然
- 入力画像を解析
- なぜマイクロソフトペイントのように簡単にできるのか
- 旧方式: ユーザーが画像の編集領域を切り取って AI に渡す必要があった。
- 新方式: AIが自動で「編集領域を検出」して「背景と融合」までやる。
- これは 大規模画像-テキストペアの事前学習により、位置指定や文脈理解の能力が大きく向上したため。
イメージとしては、昔は「細かく手で指示する職人さん(ControlNet)」だったのが、今は「言葉だけで意図を理解してレイアウトしてくれる優秀なデザイナー(Flux Kontext)」になった感じです。
Workflow
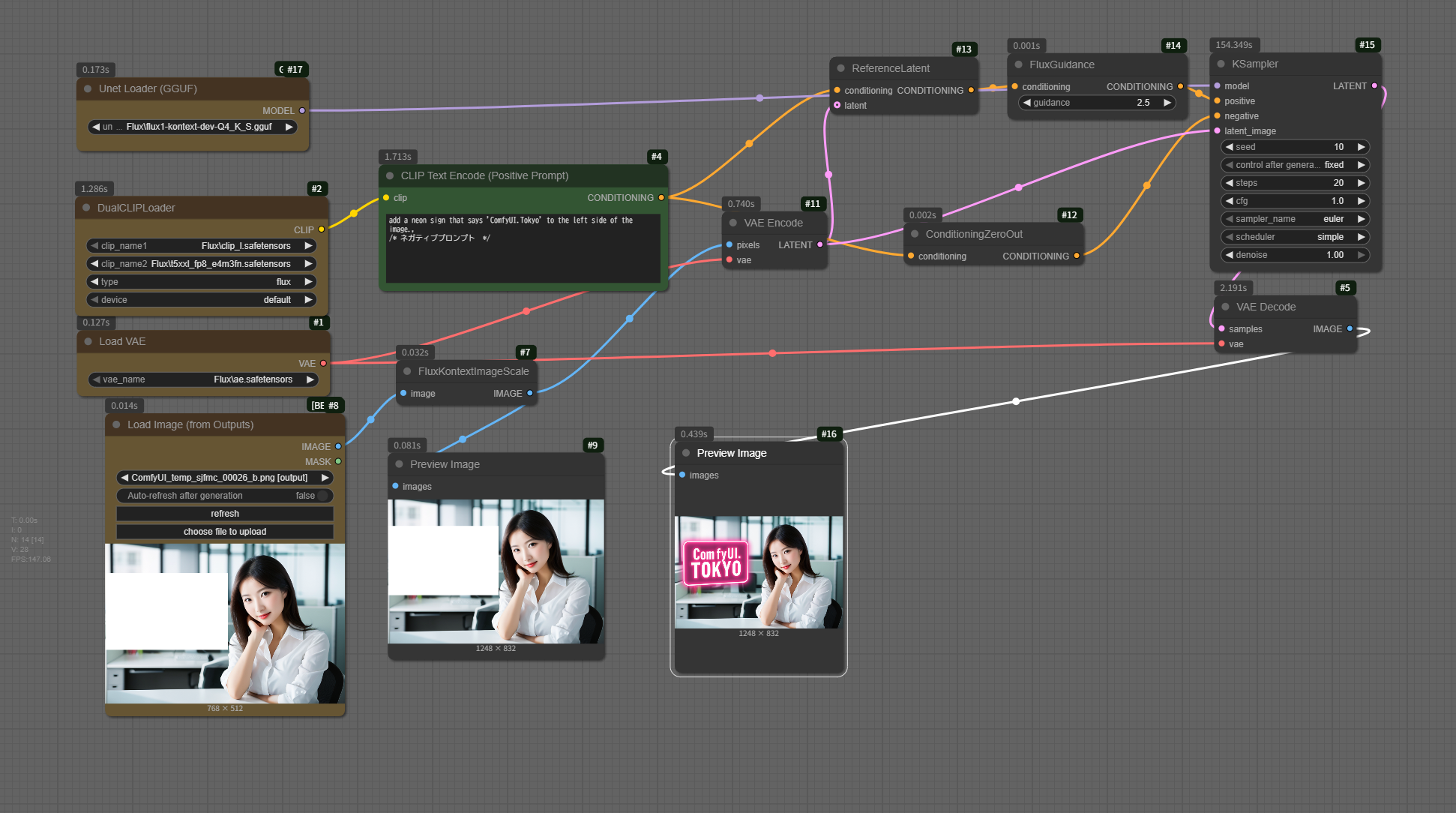
マイクロソフトペイントで書きたいエリアを白くしました。


